[ELK] Elasticsearch의 구조
Elasticsearch 구조
지난번에 기본적인 ELK stack의 설치와 실행을 확인했습니다. 이번에는 엘라스틱서치의 기본 구조부터 알아봅시다. 이번 내용은 이론적인 내용이 강해서 재미가 없을 수도 있습니다. 기본적으로 엘라스틱서치는 논리적 구조와 물리적 구조로 구분할 수 있습니다.
논리적 구조
우선 논리적 구조로는 도큐먼트(document), 타입(type), 필드(field), 인덱스(index), 매핑(mapping)로 구성됩니다.
1. 도큐먼트 (Document)
- 도큐먼트는 엘라스틱서치의 데이터 최소 단위입니다. JSON 오브젝트 하나를 일컫습니다. 이 형태는 MongoDB와 같은 NoSQL에서도 사용을 하고 있습니다. 도큐먼트는 내부에 여러가지 필드로 구성되어 있습니다. 특이한 점이라면 도큐먼트 내부의 필드 구성을 도큐먼트로 할 수 있습니다. 이를 Embedded documents라고 MongoDB에서는 말합니다.
2. 타입 (Type)
- 여러 개의 document가 모여서 하나의 type을 형성합니다. 하지만 elasticsearch 7.0버전 이후부터 mapping type, 일명 타입이 삭제가 됩니다. 이는 엘라스틱서치의 인덱싱 방식과 어느정도 연관이 있습니다.
- 엘라스틱 서치가 빠른 검색 속도를 갖는 이유는 엘라스틱서치의 인덱싱 방식때문입니다. 여러 도큐먼트에는 다양한 필드가 존재합니다. 이때 RDB와 다르게 엘라스틱서치는 다른 타입에 존재하는 동일한 이름의 필드는 동일한 Lucene (루씬)필드에 지원합니다. 이렇게 될 경우 타입이라는 제약때문에 필드의 삭제, 수정이나 필드의 공통부분이 부족한 경우에 Lucene의 효율적 데이터 압축기능을 저해한다는 이유로 타입은 삭제가 되었고 인덱스가 역할을 대신합니다. (이해하지 못하셔도 괜찮습니다. 어차피 설명에서는 타입을 활용을 할 예정입니다.)
3. 필드 (Field)
- 필드는 도큐먼트의 데이터 타입입니다. 일반적으로 RDB의 column과 유사하다고 설명하지만 엄밀히는 틀린 말입니다. 엘라스틱서치의 빠른 검색 속도가 보장되는 이유는 필드에 저장된 데이터 토큰을 살려서 인덱싱이 진행되기 때문입니다. 실제 공식 문서에 따르면 도큐먼트를 검색 토큰으로 변환하여 해당 토큰이 저장된 도큐먼트를 연결합니다. 이를 역 인덱스 (Inverted Index)라고 합니다.
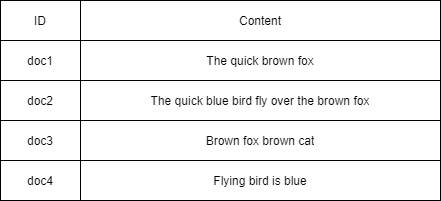
위의 도큐먼트가 저장되어 있다고 가정하면 엘라스틱서치는 아래와 같이 인덱싱을 진행합니다.
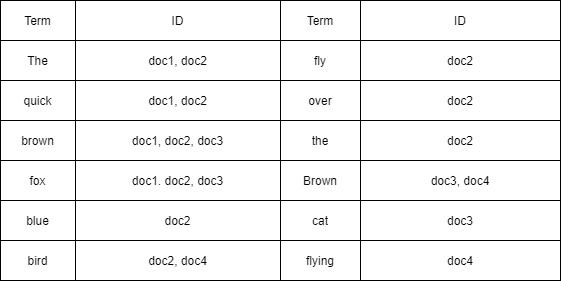
결과적으로 완전히 새로운 단어가 추가되는 경우가 아니면 데이터가 추가되어도 탐색하는 값이 늘어나지 않는 경우가 발생합니다. 따라서 굉장히 빠른 속도로 검색이 가능합니다.
4. 인덱스 (Index)
- 인덱스는 인덱싱과정의 결과물을 말합니다. 도큐먼트들이 모여있는 집합체를 일컫기도 합니다. 엘라스틱서치에서는 인덱스라는 단어가 많이 사용되기 때문에 데이터의 저장단위는 인디시즈(indices)라고 말합니다. 인덱스는 기본적으로 샤드 (shard)라는 단위로 구분되어 저장됩니다. 샤드의 자세한 설명은 물리적 구조 설명에서 설명드리겠습니다. 7.x 버전에서는 디폴트로 1개의 샤드로 구성이 됩니다. 이 1개의 샤드는 프라이머리 샤드(primary shard)라고 부릅니다. 6.x버전에서는 5개의 샤드로 구성이 되었습니다. 기본세팅을 기준으로 말씀드리면 분산저장을 할 경우 5개의 프라이머리 샤드와 1개의 레플리카 샤드(Replica shard)로 구성됩니다. 자세한 설명은 이어지는 물리적 구조에서 설명드리겠습니다.
물리적 구조
물리적 구조는 노드 (node), 샤드 (shard)로 구성됩니다. 이 2가지를 설명하기에 앞서 모든 것의 기반이 되는 클러스터 (cluster)를 설명하겠습니다.
0. 클러스터 (Cluster)
- 클러스터는 엘라스틱서치의 가장 큰 시스템 단위입니다. 최소 1개 이상의 노드를 갖고 있으며 각 노드는 샤드로 구성됩니다. 서로 다른 클러스터는 독립적으로 유지되며 여러 서버가 하나의 클러스터를 구성하기도 하고 한개의 서버가 여러 개의 클러스터를 관리할 수도 있습니다.
1. 노드 (Node)
- 노드는 엘라스틱서치의 클러스터에 있는 일종의 서버입니다. 노드에서 반드시 1개는 마스터 노드 (Master node)역할을 수행합니다. 그리고 도큐먼트를 관리하는 데이터 노드 (Data node)가 존재합니다. 이 외에도 더 존재하지만 설명은 나중에 진행하겠습니다.
- 마스터 노드(Master node)는 노드 추가/제거, 인덱스 생성/삭제, 인덱스 메타 데이터 관리, 샤드의 위치와 같은 클러스터의 전반적인 정보와 상태를 관리하는 역할을 담당합니다.
마스터 노드 설정은 elasticsearch.yml에서 할 수 있습니다. 디폴트로 node.master: true로 설정된 경우 모든 노드가 마스터 노드의 후보(마스터 후보 노드)가 됩니다. 이 경우 현재 마스터 노드가 특정 이유로 동작을 중지하는 경우 클러스터가 동작을 중지하는 것을 막기 위해 마스터 후보 노드 중 1개가 마스터 노드가 됩니다. 마스터 후보 노드들은 이미 마스터 노드의 정보를 모두 공유하기 때문에 바로 이어서 마스터 노드의 역할을 수행할 수 있습니다.
하지만 클러스터의 규모가 커지며 노드와 샤드의 수가 많아지는 경우 모든 노드가 마스터 노드의 정보를 공유하는 것은 클러스터 자체에 과부하를 일으킬 위험이 존재합니다. 마스터 노드는 많은 정보를 담고 있는데 모든 노드가 방대한 양의 정보를 저장, 관리하면 그만큼의 용량이 증가하니까요. 이를 위해 마스터 후보 노드가 되지 않는 노드는 node.master를 false로 설정하여 관리해줍니다.
- 데이터 노드(Data node)는 실제로 인덱싱이 된 데이터를 저장한 노드입니다. 이때, 마스터 후보 노드와 데이터 노드는 엄격하게 분리하여 각자의 역할을 수행하도록 하는 것이 중요합니다. 그래서 마스터 후보 노드들은 node.data: false로 설정하여 마스터 노드의 역할만 수행하게 합니다. 이를 통해 마스터 노드는 데이터 저장에는 관여하지 않고 클러스터 관리에 집중하며 데이터 노드는 단순 데이터 처리 작업에만 집중할 수 있습니다. 실제 분산 저장이 되는 샤드가 위치하는 노드가 데이터 노드입니다. 또한 데이터 처리 작업이 집중적으로 일어나기 때문에 리소스 모니터링이 필요합니다.
2. 샤드 (Shard)
- 샤드는 인덱싱된 데이터가 여러 개의 부분으로 인덱스 내부에 분산 저장되어 있습니다. 이런 분산 저장이 엘라스틱서치의 핵심 저장방식입니다. 이렇게 나눠진 부분을 샤드라고 부릅니다.
엘라스틱 서치는 기본적으로 인덱스를 5개의 샤드로 나누어서 저장합니다. 이런 방식때문에 데이터의 크기를 수평적인 확장이 가능하고 작업이 여러 샤드에서 동시적으로 작업이 가능하여 병렬 작업이 가능합니다. (이는 NoSQL방식을 사용하는 많은 DB의 장점입니다.) 일반적으로 프라이머리 샤드(Primary shard)와 레플리카 샤드(Replica shard)로 구성됩니다.
- 프라이머리 샤드(Primary shard)는 처음 생성된 샤드입니다. 데이터의 원본을 갖고 있으며 데이터 업데이트 요청이 들어올 경우 반드시 프라이머리 샤드에 요청이 수행됩니다. 그리고 해당 요청의 내용은 레플리카 샤드에 복제됩니다.
- 레플리카 샤드(Replica shard)는 프라이머리 샤드에 문제가 발생할 경우 복구작업을 위한 샤드입니다. 프라이머리 샤드의 데이터가 무너질 경우 대신해서 프라이머리 샤드의 역할을 수행합니다. 복제본이라고 부르기도 합니다.
쉽게 이해를 하기위해 엘라스틱 가이드북 설명을 가져오겠습니다. 1개의 인덱스가 있을때, 5개의 샤드로 구성되고 4개의 노드로 이루어져 있다고 가정합니다. 이 경우 5개의 프라이머리 샤드와 5개의 레플리카 샤드가 4개의 노드에 분산되어 저장됩니다.

이때 같은 샤드와 복제본은 반드시 서로 다른 노드에 저장됩니다. 노드는 일종의 서버라고 했었죠? 만약 서버가 네트워크 문제같은 어떤 문제가 발생하여 작동을 정지하면 해당 노드의 정보를 어떻게 처리할까요?

위처럼 3번 노드가 작동을 중지하면 0번과 4번 샤드의 데이터를 잃게 됩니다. 이때 클러스터의 동작 순서는 다음과 같이 흘러갑니다.
1) 클러스터는 우선 유실된 노드의 복구를 기다립니다. 만약 노드가 복구된다면 그대로 진행하면 되지만 타임아웃이 지날 경우 노드의 복구가 어렵다고 판단되면 샤드 복구 작업에 들어갑니다.
2) 우선 복제본을 잃은 샤드를 확인합니다. 0번과 4번 샤드는 복제본이 사라져 1개의 샤드만 남아있습니다. 이 샤드의 레플리카 샤드를 다른 노드에 저장합니다.
3) 이렇게되면 모든 샤드의 복구가 완료하여 전체 샤드의 개수가 유지되고 노드 유실이 발생해도 데이터 무결성과 가용성을 보장합니다.

최종적으로는 다시 위의 사진처럼 데이터 복구가 완료됩니다. 만약 프라이머리 샤드가 유실되는 경우에는 기존에 존재하는 레플리카 샤드가 프라이머리 샤드로 승격되고 다른 노드에 해당 샤드를 복제하는 과정이 수행됩니다.
이렇게 길고 긴 엘라스틱서치 구조를 알아봤습니다. 이 내용은 사실 어렵고 재미없지만 상당히 중요합니다. 구조를 알아야 엘라스틱서치의 활용도를 최대한으로 끌어낼 수 있기 때문입니다. 그래서 좀 지루하더라도 잘 읽어보시면 좋겠습니다.
다음시간에는 본격적인 엘라스틱서치 사용을 알아보겠습니다.
'Infra > ELK' 카테고리의 다른 글
| [ELK] Elasticsearch 활용과 Rest API (0) | 2021.07.14 |
|---|---|
| [ELK] WSL을 통한 ELK 설치 및 실행 (0) | 2021.07.08 |