[Data Structure] Priority Queue (우선순위 큐)
Priority Queue (우선순위 큐)
이전에 큐에 대해서 배운 적이 있다. 이렇게 일반적인 큐를 FIFO Queue라고 한다. FIFO원리를 갖고 있는 큐이기 때문이다.
이번 시간에는 다른 성질을 갖는 우선순위 큐에 대해서 이야기해보겠다.
우선순위 큐는 이름에 특징이 잘 나와있는데, 큐의 pop 연산수행을 진행할 때, 프로그래머가 정해놓은 우선순위에 맞춰서 제거 연산을 진행한다.
일반적으로는 우선순위 기준은 2가지인데,
- 크기가 큰 값을 우선순위로 두는 Max-Priority-Queue
- 크키가 작은 값을 우선순위로 두는 Min-Priority-Queue
가 있다.
우선순위 큐와 큐는 잘 알아둘 필요가 있는 이유가 있다. 이전 글에서 트리의 탐색 방식은 향후 그래프 탐색방법인 DFS와 일맥상통한다고 했다. 큐는 그래프 탐색방법 중 BFS에서 사용이 된다. 그리고 그런 BFS의 응용으로 사용하는 최단거리 계산 알고리즘인 다익스트라(Dijkstra) 알고리즘에서는 Min-Priority queue가 사용된다. 이 글에서는 Min-priority queue를 기준으로 구현하겠다.
Priority Queue ADT
우선순위 큐는 entry들의 모임이다. 여기서 entry란 새롭게 나오는 개념인데, (key, value)조합으로 이루어진 데이터 쌍이다. value는 없는 경우도 있는데, key는 반드시 존재하게된다. key값으로 우선순위를 결정하기 때문이다.
- insert(e) : e라는 값을 가진 entry 삽입 (여기서는 e는 key가 된다.)
- removeMin() : 가장 작은 값을 삭제해준다.
- min() : 가장 작은 값을 반환해준다.
- size()
- empty()
우선순위 큐 구현방법
우선순위 큐 구현방법에는 3가지 방식이 존재한다. 이유는 정렬 방식때문인데, 가장 효율적인 방법은 힙(heap)방식으로 구현하는 것이다.
- unsorted sequence
- sorted sequence
- heap
Sequence based Priority Queue
시퀀스 기반의 우선순위 큐에는 2가지가 있는데, unsorted방식과 sorted방식이다. 이 두 가지 방식의 구현 원리를 설명해보겠다.
Unsorted Sequence & Selection sort
- 기본 함수의 소요시간
비정렬 방식의 삽입연산에는 \(O(1)\)의 시간이 소요된다. 이유는 가장 마지막이나 가장 앞에 데이터를 넣어주기만 하면되기 때문이다.
removeMin 연산이나 최소를 반환하는 연산같이 탐색을 동반하는 연산은 모두 \(O(n)\)시간을 요구한다. 왜냐하면 전체 데이터에서 가장 작은 값을 찾기 위해서는 모든 값을 확인해야하기 때문이다. - 선택정렬 (Selection sort)
비정렬 방식으로 만든 우선순위 큐를 사용하는 정렬방식이 선택정렬이다.
정렬하고자하는 sequence의 내부 데이터를 모두 우선순위 큐에 넣었다가 다시 앞에서부터 제거하면서 빼내는 절차를 거쳐야한다.- 선택정렬의 삽입 과정에서는 \(O(n)\)시간이 소요된다. 이유는 간단하다. 우선 비정렬 시퀀스에 넣은 값을 다시 앞에서부터 우선순위 큐에 삽입해주기 때문이다. 그래서 총 n번의 \(O(1)\)연산이 수행되므로 총 \(O(n)\)시간이 소요된다.
- 선택정렬에서 removeMin은 \(O(n^2)\)시간이 소요된다. 앞서 말했듯이 비정렬방식에서는 removeMin을 위해서는 저장된 데이터만큼의 탐색을 진행해야한다. 그래서 총 n개라 했을 때 n번 탐색, 이후 n-1번 탐색을 1번 탐색까지 반복하므로 등차수열 합 공식을 적용 시킬 수 있다.
\[\sum_{k=1}^{n}k = \frac{n(n+1)}{2}\]
Sorted Sequence & Insertion sort
- 기본 함수의 소요시간
정렬 방식에서 삽입연산은 \(O(n)\)시간이 소요된다. 해당 데이터가 들어가기 가장 좋은 위치를 탐색해야하기 때문이다. 정확히 말하면 데이터를 삽입하는 동시에 삽입정렬이 이루어지기 때문이다.
removeMin은 이미 삽입당시 정렬이 이루어졌으므로 \(O(1)\)시간으로 가장 앞에 데이터를 제거해주면 된다. - 삽입정렬 (Insertion sort)
정렬 방식으로 구현한 우선순위 큐를 사용하는 정렬방식이 삽입정렬이다. 정렬하고자하는 sequence의 내부 데이터를 모두 우선순위 큐에 넣었다가 다시 앞에서부터 제거하면서 빼내는 절차를 거쳐야한다.- 삽입정렬의 삽입과정은 \(O(n^2)\)의 시간이 사용된다. 우리가 정렬하고자 하는 시퀀스의 데이터를 우선순위 큐에 넣을 때 우선순위 큐에 들어온 데이터의 크기만큼 탐색을하며 자신이 들어갈 위치를 찾는다. 결국 전체 데이터만큼 탐색을 해야하는데, 이때 \(O(n)\)시간이 걸리게된다. 선택정렬에서 제거하는 원리처럼 등차수열 합공식에 의해서 \(O(n^2)\)시간이 걸린다.
- 다행히 removeMin은 \(O(n)\)시간이 걸린다. 가장 앞의 데이터를 빼주면 되므로 \(O(1)\)만큼의 연산은 전체 데이터 횟수만큼 해주기 때문이다.
Heap (힙)
힙은 우선순위 큐의 구현방법 중 하나이다. 완전이진트리 구조로 데이터를 저장하고 있다. 우선순위 큐의 구현을 위한 것이므로 entry를 저장하고 있다. 힙에 반드시 필요한 2가지가 있다.
- heap-order : 힙 순서는 힙에서 데이터 삽입과 제거 과정에서 필요한 것이다. 부모와 자신의 데이터를 비교해서 두 노드의 정보를 바꿔줄 필요가 있다.
- 완전 이진트리 구조 : 노드의 제거와 삽입에서 사용하는 upHeap과 downHeap과정에서 좌우 노드의 탐색이 필요하기 때문에 반드시 왼쪽부터 꽉 채워지는 완전 이진트리 구조를 가져야한다.
- last node : 삽입하는 과정에서 보다는 제거하는 과정에서 필요한 마지막 노드를 가져오는 last node의 정보를 가져와야한다. last node는 말 그대로 가장 깊이 있는 노드 중 하나이다.
힙의 깊이와 노드 개수의 연관성
힙의 깊이와 노드 개수는 연관성이 깊다. 왜 갑자기 힙 트리의 높이를 계산하냐면 이후에 필요한 upHeap이나 downHeap 과정은 힙 트리의 높이가 결국 수행시간을 결정하게 되기 때문이다.
완전 이진트리를 기준으로 할 때, 현재 이진트리가 h-1까지 구성되어있고 새로 데이터를 넣으면 깊이 h에 새로운 노드가 삽입되는 상황이라고 하자.
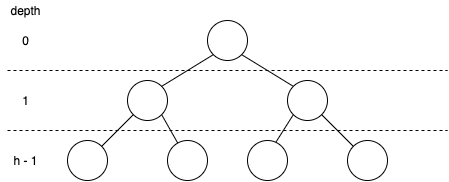
현재까지 노드개수를 수식으로 표현하면 다음과 같다.
\[
1 + 2+ 2^{2}+...+2^{h-1}=\frac{1(2^h -1)}{2-1}=2^h -1
\]
깊이가 h-1인 상황에서 완전 이진트리가 되어 있는 경우는 \(2^h -1\)개의 노드가 있다. 여기서 만약 노드가 1개 추가된다면 h높이에 노드가 1개 추가된다.

이전까지 \(2^h -1\)개의 노드가 1개가 추가되면서 \(2^h\)개가 된다. 즉 h높이 트리 노드 개수는 다음과 같은 수식을 만족한다.
\[
n \geq 2^h \rightarrow ; h \leq \log_{2}{n}
\]
결과적으로 높이와 관련된 연산은 \(O(logn)\)연산 수행시간이 걸린다.
insertion of heap (힙의 삽입과정)
힙은 새로운 노드를 삽입하거나 제거를 했을 때 기본적으로 데이터가 정리가 되어 있는 트리의 형태를 띄게된다.
우선순위 큐의 구현을 위해 만들어지므로 어떻게 보면 데이터 정렬이 당연해질 수 있다. 최소 힙을 기준으로 할 때, 루트 노드는 자연스럽게 가장 작은 값을 갖게되고 리프노드일수록 큰 값을 갖게된다.

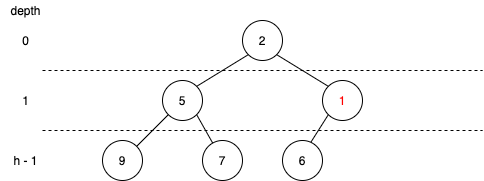
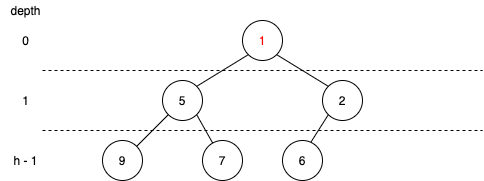
- 새로 들어 온 노드와 자신의 부모노드와 크기 비교를 한다.
- 자신의 부모노드가 자신의 값보다 크기가 크다면 둘의 데이터를 바꿔준다. 아니라면 그대로 유지하고 함수를 종료
- 1번과 2번을 바꿀 수 없을 때까지 반복해준다.
두 노드의 값을 변경하는 과정은 \(O(1)\)시간이 소요된다. 이 과정을 최악의 경우 (리프 -> 루트)에 트리의 높이만큼 swap을 해줘야한다. 위에서 h는 아무리 최악이라도 \(\log_{2}{n}\)을 넘을 수 없다. 결국 힙의 삽입과정에서 소요되는 총 시간은 \(O(\log{n})\)시간이다.
이렇게 힙의 삽입과정에서 정렬을 해주는 과정을 upheap이라고 한다. 위로 올라가는 형태이기 때문에 붙여진 이름이라고 생각하면된다.
removal of heap (힙의 삭제과정)
힙에서 삭제를 하게 될 경우 루트노드를 제거하게된다. 왜 루트노드를 제거하냐면 힙은 우선순위 큐의 구현을 위해 만들어진 방식인데, 우선순위 큐는 특정한 기준치를 따라서 Out과정이 이루어진다. 그 특정한 기준치로 데이터를 높이별로 정렬을 시킨 것이 바로 heap이기 때문이다.
그렇다면 루트 노드가 제거되었다면 그 자리는 누가 차지하게 되는 걸까?
그 자리는 가장 마지막 노드가 우선적으로 차지하게 된다.
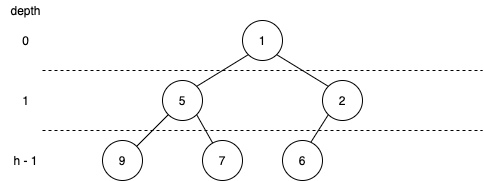
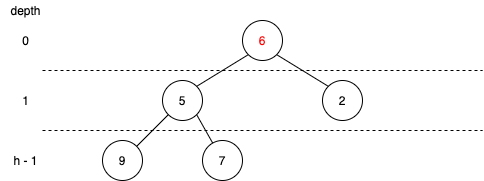

- 우선 루트노드를 제거한다. 제거하기 이전에 가장 마지막 노드를 저장해준다. (가장 마지막 노드를 지시하는 방법은 힙의 크기를 저장하는 변수로 지시해주면 된다.)
- 그 후 루트노드 위치 (벡터 인덱스 1번)에 저장해 둔 마지막 노드 데이터를 넣어준다. 그와 동시에 마지막 노드 데이터를 벡터에서 제거해준다.
- 그 후 자식 노드에서 더 작을 것과 위치를 바꿔준다.
- 3번 과정을 더 이상 바꿀 수 없을 때까지 반복한다.
이 과정도 삽입과 동일하게 \(\log_{2}{n}\시간이 소요된다. 자식과 데이터를 바꾸는 과정은 downheap이라고 하는데, 사실 upheap은 루트노드라는 쉬운 종결조건이 있다. 하지만 downheap은 조건이 명확하지 않으면 벡터의 out of index에러를 마주친다.
종결조건은 자신의 key값이 자신의 자식들의 key값 중 어떤 것보다도 크지 않거나 본인의 위치가 리프노드면 종결한다.
Heap implementation (힙 구현)
Heap prototype
#include <iostream>
#include <vector>
using namespace std;
enum direction { MIN = 1, MAX = -1 };
class Heap {
private:
vector<int> Node;
int heap_size;
int root_idx;
int direction;
public:
Heap(int direction) {
Node.push_back(-1);
this->heap_size = 0;
this->root_idx = 1;
this->direction = direction;
}
void Swap(int idx1, int idx2);
void upHeap(int idx);
void downHeap(int idx);
void insert(int data);
int pop();
int top();
int size();
bool empty();
void print();
int at();
};특별히 설명하고 넘어갈 부분은 enum class파트의 역할과 벡터에 -1을 넣고 시작하는 이유정도이다.
우선 enum class인 direction의 역할은 Max heap과 Min heap을 결정해준다. 여기서 왜 MIN이 1이고 MAX가 -1이냐면, 기본적으로 이후에 진행할 upHeap과 downHeap과정에서 부등호로 대소비교를 해준다. 우리가 구현할 힙은 최소 힙을 기준으로 하므로 우선 MIN이 1이 된다. 여기서 부등호에 -1을 곱해주면 부등호 방향이 바뀜을 활용해주면 된다. 그래서 MAX가 -1이 되는 것이다.
벡터에 -1이 먼저 들어가는 이유는 간단하다. 우리는 앞서서 본 트리에서 벡터나 배열로 이진트리를 구현할 경우를 생각해봤다. 이진트리의 특성상 left child의 인덱스는 parent index * 2와 같고 right child는 left child + 1의 인덱스를 갖는다. 이런 성질은 문제없이 활용하기 위해서는 어떤 수에 0을 곱해도 0인 0번 인덱스를 피하고 데이터를 다뤄줘야한다. 그래서 우선적으로 0번 인덱스에 의미없는 수를 넣어준다.
empty, size, top, at function
bool empty() {
return heap_size == 0;
}
int size() {
return heap_size;
}
int top() {
return Node[root_idx];
}
int at(int idx) {
return Node[idx];
}간단한 반환 함수들이다. 설명은 생략...
Swap function
void Swap(int idx1, int idx2) {
int tmp = Node[idx1];
Node[idx1] = Node[idx2];
Node[idx2] = tmp;
}일반적인 swap과 유사하다. 여기서 조금 주의해야할 점은 이름의 s는 반드시 대문자로 설정해주다. Visual Studio에는 기본적으로 swap이 있는데, 이게 헤더를 추가하지 않아도 사용이 가능한 구현함수라 사용할 때 문제가 발생할 수 있다.
upheap function
void upHeap(int idx) {
if (direction * Node[idx/2] > direction * Node[idx]) {
Swap(idx/2, idx);
upHeap(idx/2);
}
}heap에서 가장 중요한 함수 중 하나인 upheap 함수다. upheap을 진행할 때 기억할 중요한 점은 부모의 값과 자신의 값 비교 이다. C++성질상 나눗셈의 최솟값은 0이므로 무조건 0번 인덱스까지만 간다. 그래서 그냥 단순 재귀로 계속 연산해주면 된다. 재귀 실행조건은 간단하다.
부모가 나보다 큰 경우이다. 이 경우에는 위에서 구현한 Swap을 실행시켜주고 다시 재귀로 upheap을 돌려주면된다. 재귀로 돌려줄 때는 자신이 이미 부모와 위치가 바뀌었으므로 부모인덱스를 인덱스로 넣어준다.
downheap function
void downHeap(int idx) {
int right = 2 * idx + 1;
int left = 2 * idx;
int small = right;
if (right <= heap_size) {
if(direction * Node[left] <= direction * Node[right]) {
small = left;
}
}else if (left <= heap_size) {
small = left;
}else {
return;
}
if(direction * Node[idx] > direction * Node[small]) {
Swap(small, idx);
downHeap(small);
}
}heap구현에서 가장 어려운 부분이지 않을까 싶은 downheap이다. 앞에서 말한 downheap의 조건을 우선 잘 적어보자.
- 자신이 리프노드에 도달하면 멈춘다.
- 자신보다 자신의 자식중 작은 자식이 자신보다 작지 않으면 멈춘다.
이걸 잘 생각해보면 우선 우리가 해줘야 할 작업이 몇 가지가 있다.
- 어떻게 하면 지금 내가 있는 위치가 리프노드인지 알 수 있을까?
- 이건 어렵지 않다. 힙의 기본조건은 완전 이진트리라는 것이다. 우리는 이미 삽입과 삭제를 할 때, 힙에 저장된 노드 수를 기록하는 heap_size를 갖고 있다. 이진트리 성질에 따라서 만약 right나 left노드의 인덱스가 heap_size를 넘었다면 적어도 현재 노드에는 자식이 존재할 수 없다는 의미가 된다. 그러면 현재 노드는 자연스럽게 리프노드가 된다.
위의 코드에서는 첫번째 if~else if문이 그 역할을 한다.
- 이건 어렵지 않다. 힙의 기본조건은 완전 이진트리라는 것이다. 우리는 이미 삽입과 삭제를 할 때, 힙에 저장된 노드 수를 기록하는 heap_size를 갖고 있다. 이진트리 성질에 따라서 만약 right나 left노드의 인덱스가 heap_size를 넘었다면 적어도 현재 노드에는 자식이 존재할 수 없다는 의미가 된다. 그러면 현재 노드는 자연스럽게 리프노드가 된다.
- 자신의 자식 중 작은 것을 찾아야 한다.
- 만약 내가 리프노드가 아니고 자식이 있다는 것을 파악했다면, 이제 자식 중 작은 값을 찾아내서 나와 비교 후 자리를 바꿔줘야한다. 첫번째 if~else문에서 리프노드가 아님을 파악했다면, 내가 자식이 1개인지, 2개인지 알아볼 필요도 있다.
right가 heap_size보다 작거나 같다는 의미는 나에게 자식이 2개가 있다는 의미가 된다. 완전 이진트리의 특징상 right node index는 left node index보다 무조건 클 수 밖에 없기 때문이다. 그리고 left가 없다면 right도 있을 수 없기 때문이다. 즉 right가 존재할 때만 left와 right의 값을 비교해준다.
left만 있다면 비교할 인덱스는 left 하나 뿐이다.
- 만약 내가 리프노드가 아니고 자식이 있다는 것을 파악했다면, 이제 자식 중 작은 값을 찾아내서 나와 비교 후 자리를 바꿔줘야한다. 첫번째 if~else문에서 리프노드가 아님을 파악했다면, 내가 자식이 1개인지, 2개인지 알아볼 필요도 있다.
그 후 upheap과 유사하게 재귀로 진행을 해주면된다. 우리가 고려해줄 것들은 이미 위쪽의 if~else문에서 다 고려해줬다.
insert, pop function
void insert(int data) {
Node.push_back(data);
heap_size++;
upHeap(heap_size);
}
int pop() {
if(empty()) {
return -1;
}
int tmp = Node[heap_size];
int ret = Node[root_idx];
Node.erase(Node.begin() + heap_size);
Node[root_idx] = tmp;
heap_size--;
downHeap(root_idx);
return ret;
}우선 삽입함수부터 설명을 해보면, 간단하다. 앞서 말했듯이 우선 노드를 넣어주고 upheap과정을 통해 정렬을 진행해주면 된다.
조금 복잡한 제거함수이다. 우선 제거관련이므로 당연하게 공백여부를 체크해준다. 그 후 마지막노드 값을 임시적으로 보관해준다. 이 값은 제거된 root에 대신 들어가게된다.
말은 root를 없애는 것처럼 보이지만 실제로는 root의 값만 바꾸고 실제 제거되는 데이터 위치는 마지막 노드의 위치이다. vector function으로 마지막 노드부분을 제거해준다.
그 후 root의 값을 마지막 노드 값으로 바꾸고 downheap을 진행해주면된다.
당연히 반환 값은 root에 저장되었던 값.
print function
void print() {
if(empty()){
cout << -1 << "\n";
}else{
for(int i = 1; i <= heap_size; i++) {
cout << Node[i] << " ";
}
cout << "\n";
}
}출력함수에서 주의할 점은 우리가 1번 인덱스부터 데이터를 처리했다는 것이다. 이 점을 주의하면서 heap size에 맞춰서 돌려주면된다.
'Computer Science > 자료구조' 카테고리의 다른 글
| [Data Structure] Binary Search Tree (이진 탐색 트리) (0) | 2021.06.24 |
|---|---|
| [Data Structure] Hash (해시) (0) | 2021.06.24 |
| [Data Structure] Binary Tree (이진트리) & Tree 구현 (0) | 2021.06.24 |
| [Data Structure] Tree (트리) (0) | 2021.06.24 |
| [Data Structure] Vector and List (벡터와 리스트) (0) | 2021.03.03 |